
One of the key planned outputs of the CLEOPATRA project is its Open Event Knowledge Graph (OEKG). Its second version (V2.0) was released on 31 January 2021 and is built on the EventKG and several other data sets created by the Cleopatra ESR students. You can find the information at http://oekg.l3s.uni-hannover.de/, and the officially released dataset on Zenodo. The White Paper describing the second version of the OEKG, by Endri Kacupaj, Simon Gottschalk, Elena Demidova and Maria Maleshkova with contributions from the CLEOPATRA ESRs, can be downloaded here. For information on the first release of the OEKG (OEKG V1.0) published in March 2020, please read here.
The OEKG V2.0 contains more than 1 million events, in 15 languages (English, French, German, Italian, Russian, Portuguese, Spanish, Dutch, Polish, Norwegian (Bokmål), Romanian, Croatian, Slovene, Bulgarian and Danish). The OEKG is composed of seven different data sets from multiple application domains, including question answering, entity recommendation and named entity recognition. These data sets were all integrated through an easy-to-use and robust pipeline.
Datasets
The OEKG integrates seven datasets. The following table provides an overview of these datasets, including the number of triples in the OEKG. At the end of this page, there is an extended list of data set descriptions.
| Dataset | Short Description | Triples |
| EventKG light | A light-weight version of EventKG, a multilingual, event-centric, knowledge graph | 434,752,387 |
| EventKG+Click | A data set of language-specific event-centric user interaction traces | 118,662 |
| VQuAnDa | A verbalization question answering dataset | 38,243 |
| MLM | A benchmark dataset for multitask learning with multiple languages and modalities | 942,753 |
| Information Spreading | A data set for information spreading over the news | 277,992 |
| TIME | Two collections of news articles related to the Olympic legacy and Euroscepticism | 70,754 |
| UNER | The universal named-entity recognition framework | 206,622 |
| OEKG | The Open Event Knowledge Graph | 436,407,413 |
Schema
The following figure shows the OEKGV2.0 schema. This schema is based on the EventKG schema and then extended for the integration of the other six data sets.
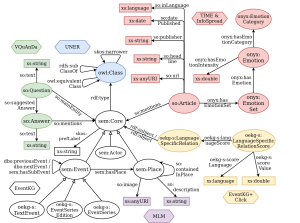
For a more detailed description of the OEKG schema and a list of the prefixes, check the OEKG website.
SPARQL Endpoint and Examples
Check http://oekg.l3s.uni-hannover.de/sparql for the SPARQL endpoint to the OEKG and selected examples demonstrating the use of the OEKG for type-specific image retrieval, hybrid question answering over knowledge graphs and news articles, as well as language-specific event recommendation.
Detailed Dataset Descriptions
The following tables provide more insights into the datasets that are integrated into the OEKG.
| Partner organization | LUH |
| Name of the dataset | EventKG |
| Description of the dataset | The EventKG is a multilingual resource incorporating event-centric information extracted from several large-scale knowledge graphs such as Wikidata, DBpedia and YAGO, as well as less structured sources such as the Wikipedia Current Events Portal and Wikipedia event lists in 15 languages. The EventKG is an extensible event-centric resource modeled in RDF. It relies on Open Data and best practices to make event data spread across different sources available through a common representation and reusable for a variety of novel algorithms and real-world applications. |
| Multilingual
(which languages) |
English, German, French, Italian, Portuguese, Russian, Spanish, Italian, Dutch, Polish, Croatian, Bulgarian, Norwegian (Bokmål), Romanian and Slovene |
| URL | http://eventkg.l3s.uni-hannover.de/ |
| Dataformat
(RDF, JSON, XML, text) |
RDF (.nq, .ttl) |
| Dataset size | ~ 150GB |
| Technical requirements (repository, libraries, …) | SPARQL |
| Licensing | Creative Commons Attribution Share Alike 4.0 International |
| Documentation | https://github.com/sgottsch/eventkg |
| Further details | Publications:
Simon Gottschalk and Elena Demidova. EventKG – the Hub of Event Knowledge on the Web – and Biographical Timeline Generation. Semantic Web Journal. In press. Simon Gottschalk and Elena Demidova. EventKG: A Multilingual Event-Centric Temporal Knowledge Graph. In Proceedings of the Extended Semantic Web Conference (ESWC 2018). SPARQL endpoint: http://eventkginterface.l3s.uni-hannover.de/sparql Example application: http://eventkg-timeline.l3s.uni-hannover.de/ |
| Partner organization | UBO |
| Name of the dataset | VQuAnDa: Verbalization QUestionANswering DAtaset |
| Description of the dataset | VQuAnDa is an answer verbalization dataset that is based on a commonly used large-scale Question Answering dataset – LC-QuAD. It contains 5,000 questions, the corresponding SPARQL query, and the verbalized answer. The target knowledge base is DBpedia, specifically the April 2016 version. |
| Multilingual
(which languages) |
No (English) |
| URL | https://figshare.com/projects/VQuAnDa/72488 |
| Dataformat
(RDF, JSON, XML, text) |
JSON |
| Dataset size | 5k samples (question, SPARQL query, answer verbalization) |
| Technical requirements (repository, libraries, …) | SPARQL |
| Licensing | Attribution 4.0 International (CC BY 4.0) |
| Documentation | http://vquanda.sda.tech/ |
| Publication | Kacupaj, Endri, et al. “Vquanda: Verbalization question answering dataset.” European Semantic Web Conference. Springer, Cham, 2020. |
| Partner organization | FFZG, KCL, LUH |
| Name of the dataset | UNER
(Universal Named Entity Recognition) |
| Description of the dataset | The dataset is composed of parallel corpora based on the content published on the SETimes.com news portal which (news and views from Southeast Europe), annotated in terms of events as defined in the ACE 2005 corpus and named entities following a new classification hierarchy composed of 3 levels:
1st level: 8 supertypes 2nd level: 47 types 3rd level: 69 subtypes |
| Multilingual
(which languages) |
Albanian, Bulgarian, Bosnian, Croatian, English, Greek, Macedonian, Romanian, Serbian and Turkish. |
| URL | TBD |
| Dataformat
(RDF, JSON, XML, text) |
XML
(BIO Index based) |
| Dataset size | 200k sentences for each language. |
| Licensing | CC-BY-SA |
| Documentation | Under development. |
| Publication | Alves, Diego, et al. “UNER: Universal Named-Entity RecognitionFramework.” CLEOPATRA – 1st International Workshop on Cross-lingual Event-centric Open Analytics, 2020. |
| Further details | Database being developed by using pre-annotation with automatic tools of the English corpus, followed by a correction step via crowdsourcing and, finally, automatically propagated to other languages.
SETimes dataset: http://nlp.ffzg.hr/resources/corpora/setimes/ |
| Partner organization(s) | UBO, TIB, JSI |
| Involved ESRs | ESR 5 (Jason Armitage), ESR 6 (Endri Kacupaj), ESR 8 (Golsa Tahmasebzadeh), ESR 12 (Swati) |
| Name of the dataset | MLM |
| Description of the dataset (2-3 sentences) | MLM is a processed data extraction from Wikidata and Wikipedia for multilingual and multimodal tasks. The primary aim is to train and evaluate systems designed to perform multiple tasks over diverse data. |
| Multilingual
(which languages) |
English, French, German |
| URL | http://cleopatra.ijs.si/goal-mlm/ |
| Dataformat
(RDF, JSON, XML, text) |
Text, geo-coordinates, triples – JSON
Images – PNG |
| Dataset size | ≈200k samples (four modalities per sample) |
| Technical requirements (repository, libraries, …) | None |
| Licensing | Creative Commons Public Licence |
| Documentation | http://cleopatra.ijs.si/goal-mlm/ |
| Publication | Armitage, Jason, et al. “MLM: A Benchmark Dataset for Multitask Learning with Multiple Languages and Modalities.” Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2020. |
| Partner organization(s) | LUH |
| Involved ESRs | ESR2 (Sara Abdollahi) |
| Name of the dataset | EventKG+Click |
| Description of the dataset (2-3 sentences) | EventKG+Click is a novel cross-lingual dataset that reflects the language-specific relevance of events and their relations. This dataset aims to provide a reference source to train and evaluate novel models for event-centric cross-lingual user interaction, with a particular focus on the models supported by knowledge graphs.
EventKG+Click consists of two subsets:
|
| Multilingual
(which languages) |
English, German, Russian |
| URL | https://github.com/saraabdollahi/EventKG-Click |
| Dataformat
(RDF, JSON, XML, text) |
TSV |
| Dataset size | 3 MB in total
4113 events in EventKG+Click_event 9119 event-centric click-through pairs in EventKG+Click_relation |
| Licensing | CC BY-SA 4.0 |
| Publication | Sara Abdollahi, Simon Gottschalk, and Elena Demidova. “EventKG+Click: A Dataset of Language-specific Event-centric User Interaction Traces.” CLEOPATRA – 1st International Workshop on Cross-lingual Event-centric Open Analytics, 2020. |
| Partner organization(s) | JSI |
| Involved ESRs | ESR11 (Abdul Sittar) |
| Name of the dataset | Information Spreading Over News |
| Description of the dataset (2-3 sentences) | This data set focuses on three contrasting events (Global Warming, FIFA world cup and earthquake). Main purpose to collect this data set is to understand information spreading patterns and detection of several barriers in events related to different domains such as sports, natural disasters and climate changes. |
| Multilingual
(which languages) |
five languages (eng, spa, ger, slv, por) |
| URL | https://zenodo.org/record/4460020#.YBNERSWVuR0 |
| Dataformat
(RDF, JSON, XML, text) |
CSV |
| Dataset size | 2682, 3147 and 1944 news articles related to FIFA world cup, earthquake, and Global Warming |
| Technical requirements (repository, libraries, …) | |
| Licensing | Creative Commons Attribution 4.0 International |
| Documentation | Each articles include meta data: id, title, body, similarity-score, class, event, article-url publisher, political-alignment, publishing time, country, country-timezone, country-economic-conditions, country-culture, and country-lat/long. This meta data will be used to create OEKG’s schema. |
| Publication | Sittar, Abdul, Dunja Mladenić, and Tomaž Erjavec. “A Dataset for Information Spreading over the News”. Conference on Data Mining and Data Warehouses (SiKDD) (2020). |
| Further details |
| Partner organization(s) | UOL |
| Involved ESRs | ESR9 (Daniela Major) & ESR10 (Caio Castro Mello) |
| Name of the dataset | TIME: Temporal Discourse Analysis applied to Media Articles |
| Description of the dataset (2-3 sentences) | During the weeks preceding the Cleopatra R&D week we defined research questions and thought about the best ways to answer them. The social scientists in the group were especially interested in analysing media texts on two different topics (the concept of Olympic legacy and the concept of Euroscepticism). The choice of media outlets also followed the logic of our research questions: the comparative approach was always a priority in both of the topics. In the case of the concept of legacy we chose to scrape data on the Rio and London Olympics in both Brazilian and British media. With Euroscepticism, our choice fell on English and Spanish media coverage. |
| Multilingual
(which languages) |
English, Portuguese, Spanish |
| URL | http://cleopatra-project.eu/index.php/2020/06/01/time-temporal-discourse-analysis-applied-to-media-articles/ |