
Over the lifetime of the CLEOPATRA project, the ESRs have worked to develop and refine demonstrators, and to make available well-documented datasets to support further research.
QuoteKG https://quotekg.l3s.uni-hannover.de/
QuoteKG is a multilingual knowledge graph of quotations from well-known figures. It contains nearly one million quotations from nearly 70,000 individuals in 55 languages. The QuoteKG creation pipeline extracts quotations from Wikiquote, a free and collaboratively created collection of quotations in many languages, and aligns different mentions of the same quotation. It also makes use of sentiment analysis.
MLM-Geo http://cleopatra.ijs.si/mlm-demo/
The MLM (Multiple Languages and Modalities) dataset is a resource for training and evaluating multi-task systems on samples in multiple modalities and three languages. The dataset is designed for researchers and developers who build applications that perform multiple tasks on data encountered on the web and in digital archives. A second version of MLM provides a geo-representative subset of the data with weighted samples for countries of the European Union.
TIME https://github.com/cleopatra-itn/TIME
TIME is a web application that allows multiple visual analyses of pre-defined cross-lingual datasets, in this case concerned with the legacy of the London and Rio Olympics and with Euroscepticism. It offers:
- headline statistics for all of the datasets included;
- a view of the most frequently appearing words and other connected information;
- a presentation of contextual links and important tags;
- cross-lingual analysis of information propagation in the form of news articles over time;
- propagation analysis showing how information spreads and how communities are generated in cross-lingual settings.
GeoWINE http://cleopatra.ijs.si/geowine/
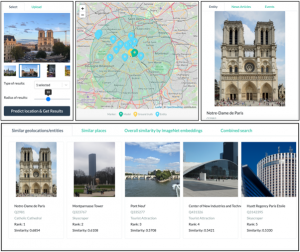 Geolocation-based Wiki, Image, News and Events Retrieval (GeoWINE) consists of five modules for retrieving related information from various sources. The first module is a state-of-the-art model for geolocation estimation of images, while the second performs a geospatial-based query for entity retrieval using the Wikidata knowledge graph. The third module exploits four different image embedding representations, which are used to retrieve the most similar entities compared to the input image. The embeddings are derived from the tasks of geolocation estimation, place recognition, ImageNet-based image classification, and their combination. The last two modules perform news and event retrieval from EventRegistry and the Open Event Knowledge Graph (OEKG).
Geolocation-based Wiki, Image, News and Events Retrieval (GeoWINE) consists of five modules for retrieving related information from various sources. The first module is a state-of-the-art model for geolocation estimation of images, while the second performs a geospatial-based query for entity retrieval using the Wikidata knowledge graph. The third module exploits four different image embedding representations, which are used to retrieve the most similar entities compared to the input image. The embeddings are derived from the tasks of geolocation estimation, place recognition, ImageNet-based image classification, and their combination. The last two modules perform news and event retrieval from EventRegistry and the Open Event Knowledge Graph (OEKG).
MIDAS/UNER http://cleopatra.ijs.si/midas/
The MIDAS demonstrator parses data from Wikipedia corpora in multiple languages, extracts named entities through hyperlinks, and aligns them with entity classes from DBpedia. This generates a named entity corpus with DBpedia class annotations which is then translated to a new complex tagging hierarchy, UNER. The final objective is to train models on recognizing and tagging named entities with a multi-tiered tagging hierarchy. This will lead to a Named Entity dataset creation workflow which works for languages covered by both Wikipedia and DBpedia, including under-resourced languages.
Latvian Twitter Sentiment Classifier http://cleopatra.ijs.si/sentimentanalyzer/demo
The demonstrator presents various pre-training strategies that aid in improving the accuracy of the sentiment classification task. Language representation models are pre-trained using these strategies and they are then fine-tuned on the downstream task. Experimental results on a time-balanced tweet evaluation set show an improvement over previous techniques, delivering 76% accuracy for sentiment analysis on Latvian tweets.