
This is the second of a series of blog posts discussing different aspects of the CLEOPATRA Research and Development week, which was held online at the end of March. The project ESRs organized themselves into groups to develop demonstrators, and this is the report from Team GOAL (Jason Armitage, Endri Kacupaj, Golsa Tahmasebzadeh and Swati Suman)
We’re a team of four researchers from different universities. We started working on MLM in December. Generating a publicly available, large-scale dataset to handle multiple modalities and languages is one of our core objectives. At the end of March, we had our first Hackathon Week for the Cleopatra project where we presented a pilot version of our demonstrator. We could say that it was a success!
Our Demonstrator revolves around MLM so, let’s check out what it’s all about.
What is MLM?
MLM is a Wikidata-generated dataset that is intended to train multitask systems. This system is anticipated to outperform single-task alternatives when simultaneously trained on task sequences. In our case, it is a system that performs both information retrieval and location estimation.
The dataset is composed of text, images, location data, and knowledge graph triples. We’re planning to release our dataset in two versions.
- The first version (MLM-v1) will contain texts with ~236k entities in three languages (English, German, and French)
- The second version (MLM-v2) will contain text with ~254k entities in ten different languages (English, German, French, Italian, Spanish, Polish, Romanian, Dutch, Hungarian, Portuguese).
Now, let’s find out why this idea for the demonstrator is worth pursuing.
Why MLM?
Systems trained on large datasets are believed to display rudimentary forms of the human ability to generalize. However, today’s systems struggle to deal with the diversity in real-world data and the ability to extend learning to new tasks.
MLM is a large-scale resource composed of different modalities and languages. It will offer the opportunity to train and evaluate multitasking systems. Such systems aim to reduce the application process complexity and boost generalization. At the same time, related applications will also benefit from machine learning models able to perform a number of independent tasks.
What did we do in the Hackathon?
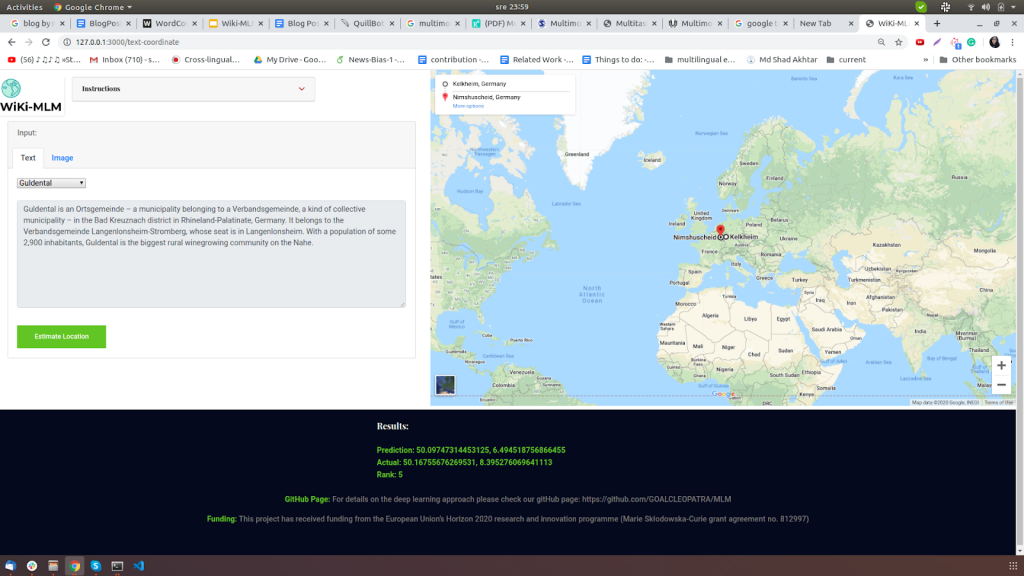
Our final aim for the week was to create a live demo visualizing the results of the geo-location estimate of our models on maps. It was important because with just the raw latitude and longitude values it is hard to tell the quality of the output. For inference, we subdivided the surface of the earth into a number of geographic cells and trained a deep neural network with geo-tagged inputs that could be either text or image.
Visualizing results on Google Maps
Now, let’s see how our demo helps to visualize the output of the model’s location prediction.
What are our goals for the next demonstrator?
We are planning to build a multitask system capable of handling multi-objective tasks. We are intending to include some or all of the following tasks using the rich data provided by MLM:
- Given a news article,
- predict locations that conceptually resemble the news story. For this task, we aim to pinpoint the locations on the map with the highest conceptual similarity based on common KG entities in news reports.
- Given a location-based image and/or text, identify semantically similar
- locations and then link to a relevant news source to collect trending articles at that location;
- locations and places similar to that. Text and/or images will also be displayed based on user preference.
- Given a coordinate, identify
- semantically similar locations;
- textual description of the location;
- image(s) that best describes the locations;
- relevant news sources to collect trending articles at that location.
How do we collaborate as a team?
To keep track of our iterative progress towards well-defined goals, we conduct bi-weekly Scrum meetings and document our work. There we organize our ideas efficiently into sprint goals and we distribute the work among us. We even exchange our thoughts, challenges, and other information between the meetings.
Jason Armitage, Endri Kacupaj, Golsa Tahmasebzadeh and Swati Suman